乳幼児ワクチンの空白期間
乳幼児ワクチンは合計3回で、2回目接種は1回目接種から3週間経過後、3回目接種は2回目から8週間経過後に接種なため、3回目を接種期限の3月31日までに打つには、1月13日までに1回目を打つ必要があったみたいです。
厚生労働省のWebページ:生後6か月~4歳の子どもへの接種(乳幼児接種)についてのお知らせ
では、「接種を行う期間は、令和4年10月24日から令和5年3月31日までです。」と書いてあり、
豊島区のWebページ:生後6か月から4歳のかた(1~3回目)
「国から示されている新型コロナウイルスワクチン接種を受けられる期間は、現時点では令和5年3月末までです。3回の接種を完了するためには、1回目の接種を、原則として令和5年1月13日までに受ける必要があります。」と書いてあります。
今日は1月14日なので、これから1回目の子はどうなるの?と思うのですが、今のところは「決まってないから打てない」ってこと変なことになりそうだと思います。(2023年1月19日追記)今のところ「打てるけど、3回目までは約束できないよ」という感じのようです。
横浜市のWebページ:乳幼児接種(生後6か月~4歳)
「現時点で、新型コロナワクチンの特例臨時接種は「令和5年3月31日まで」とされているため、様々な事情により、期間中に初回接種が完了できない場合があります。」と書いてありました。
おそらく、まったく打てないとおかしいので、3月31日までは名目上1~3回の内、どの回であっても打てるのだと思いますが、延長が決定するまで、集団接種などは計画されないと思うので、1回目を打てる場所を探すのは大変かもしれません。
(以下1月14日時点のまま)
おそらく、成人のワクチンの期間も一律、令和5年3月31日までに設定してあり、その後延長するかや有償化するかなど議論がされている中で、一番最初に期限が来てしまった乳幼児ワクチンが取り残されて、空白期間ができてしまったという感じがします。
国は乳幼児ワクチンを努力義務としており、接種開始から2か月足らずと十分に接種機会があったとはいえない状況で、空白期間を作るのは問題だと思うのですが、あまり話題にもなってないようなので、書いてみました。
仮に来週(1月16日~)あたりに、なんらかの通達で接種が延長されたとしても、集団接種の会場や打ち手の確保、予約の調整など含めて、実質的に2週間ぐらいは空白ができてもおかしくないと思います。現在、第8波の真っ只中、重症化する子もゼロではない状況で、接種機会が確保されていないというのはどうかなと思いました。
休学して
2022年10月より博士課程を1年間休学することにしました。 2018年4月に入学して以来、4年半在籍していましたが、コロナの影響が大きく、今年に入って毎月のように保育園が突然休園するなか、残り1年半で卒業は厳しいと思ったというのが一つの理由です。
もう一つあって、ふと、スーファミのトルネコの大冒険というものを思い出したので、地下に降りていくダンジョンに例えてみると、当初比較的浅い階のお宝(=卒業)を取って帰ろうと思っていたのが、もっと深い階にすごいお宝がある気がして、出てこれなくなってしまったという感じです。
浅い階のお宝も思ったより難しそうで、それに全力を掛けないと無理だとわかったわけですが、それに対するモチベーションはあまりなくなっていました。それに対し、深い階のお宝の方はあるかないかもわからないものですが、興味が続く限りはそちらを探すことにしました。
幸運にも、普段の生活以外は、ある程度自由にしても大丈夫そうな状況なので、あいた時間には興味のあることをいろいろ勉強したり考えたりしながら過ごすことになりそうです。またなにか面白そうなものがあれば、ブログなどに書いていこうと思います。
Rtが1以上でもOKな環境を考える
実効再生産数Rtは常に1以下にしなければならないか?というのは悩ましいところです。通常、Rtが1より大きいなら増え続けるので、1以下の環境を維持しなければならないという結論に至りますが、1以下を維持するにはそれなりの経済的な抑制を常時行う必要があるはずで、とても大変な状態が続くことになってしまいます。
これに対して、そうでもないようなというポイントが2点があって、1つ目は確率的にバラツキが大きいので、少数の場合は自然に消える場合が多いため、増えた時だけ抑制すれば効率的になるかもというのがあります。この点はあまりしっかりモデルを考えてはないですが、いい条件ではRtが1以上の最適解もあるかもしれません。
もう一点の考えは、感染者がゼロならゼロに何をかけ算してもゼロじゃないという考えから、市中感染が起きていない地域に関してはRtを1以上でも大丈夫なのでは?という風にも思ったりします。しかし実際100%ゼロにするのは現実的ではないので、例えば0.5人を考えたりするとそれにRt=2を掛けると結局増えていってダメなんじゃないかとも思っていました。
これにたいして、いくつか理想的な条件をつけて考えてみることで、Rtが1以上でもOKな状態を考えてみたいと思います。
条件
- A~Eの5つの10万人の市があったとして、それぞれの各市間の移動はできないとします。
実際近くの市と移動ができないなど不可能ですが、このモデルでは重要なポイントで、説明しやすい様につくった設定です。
5日毎に次の世代へ感染が発生するとして、 前世代は感染させた5日後に自然治癒とします。
警戒レベルに応じて、図のように1人⇒感染する人数と対策のコストが変わるとします。
これは市民全員が取り組む感染防止策のためのコストになります。個別の感染者発生によるコストは考えていません。例えばレベル1が5人以上の外食禁止で、レベル2が外出禁止みたいな行動を取る感じで、対策が厳しい程より経済的なコストを大きくしてあり、制限が大きいほど次の世代の感染者は少なくなります。また、レベル0⇒レベル1は1億円の差ですが、レベル1⇒レベル2は2億円の差と設定していて、より強く行動を制限をするときにはコストが大きくかかる形にしてあります。
- 各市に2人以上感染者がいないと感染者は観測できない
このコロナでは「観測」できるかというところが大きなポイントです。実際、無症状や、軽症で検査しないまま自然治癒する場合も多くあると思います。感染者が1人だと検知できなくて、2人以上だと検知できるというのは強引な設定ですが、これも説明しやすい様につくった設定です。各市は実際1人の場合、0人と区別がつかない状況ですが、実際2人以上の場合、2人以上感染者がいると検知できるので、警戒レベルを引き上げるなどの対策が打てることになります。
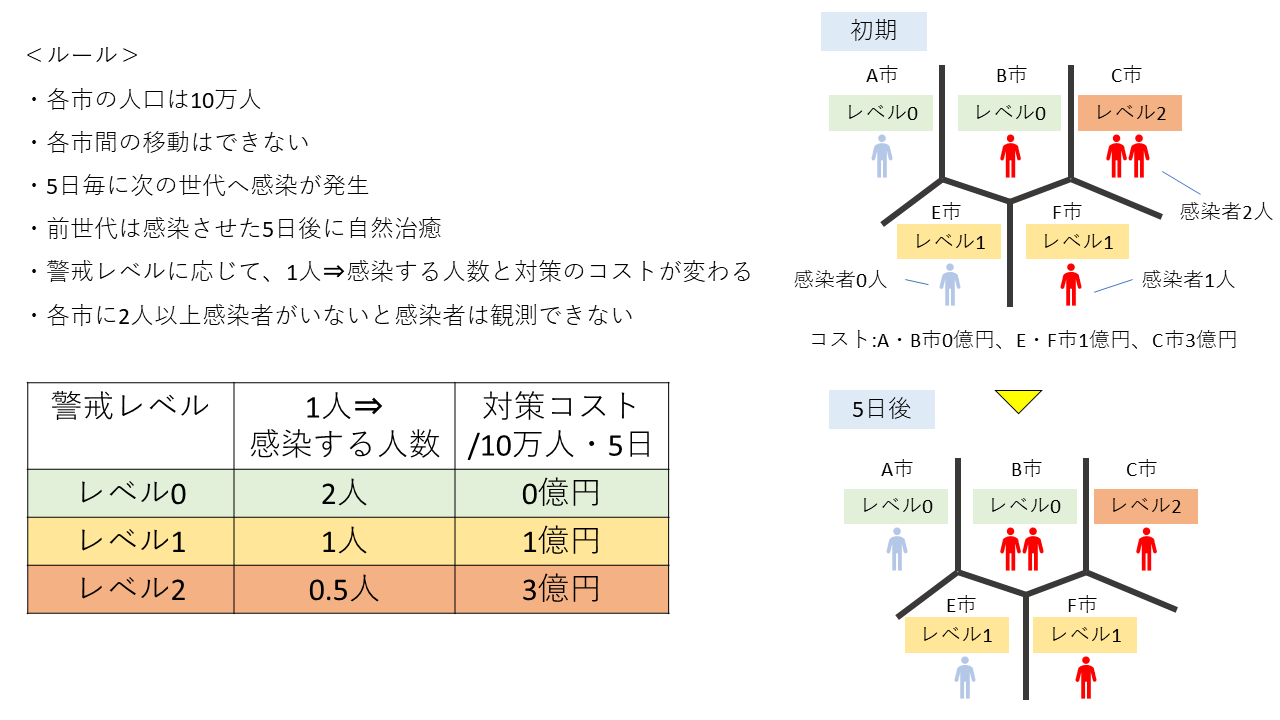
各市1人の感染者の場合
初期条件として、各市に1人ずつ感染者がいる場合を想定します。10日後の感染者の人数を初期条件と同じに抑えることを考えたとき2つのケースが考えられます。一つ目は、レベル1を維持し続けることで、1人⇒1人の感染で増やさないケースと、二つ目は最初の5日はレベル0にし、5日後に2人に増えたので、臨機応変にレベル2にして2人⇒1人に減らすというケースが考えられます。この場合、レベル2のコストを大きく設定したため、レベル1を維持した方が合計のコストが小さくなるという結果になっています。つまり、この場合はRtを1に維持した方が有利という結果になっています。
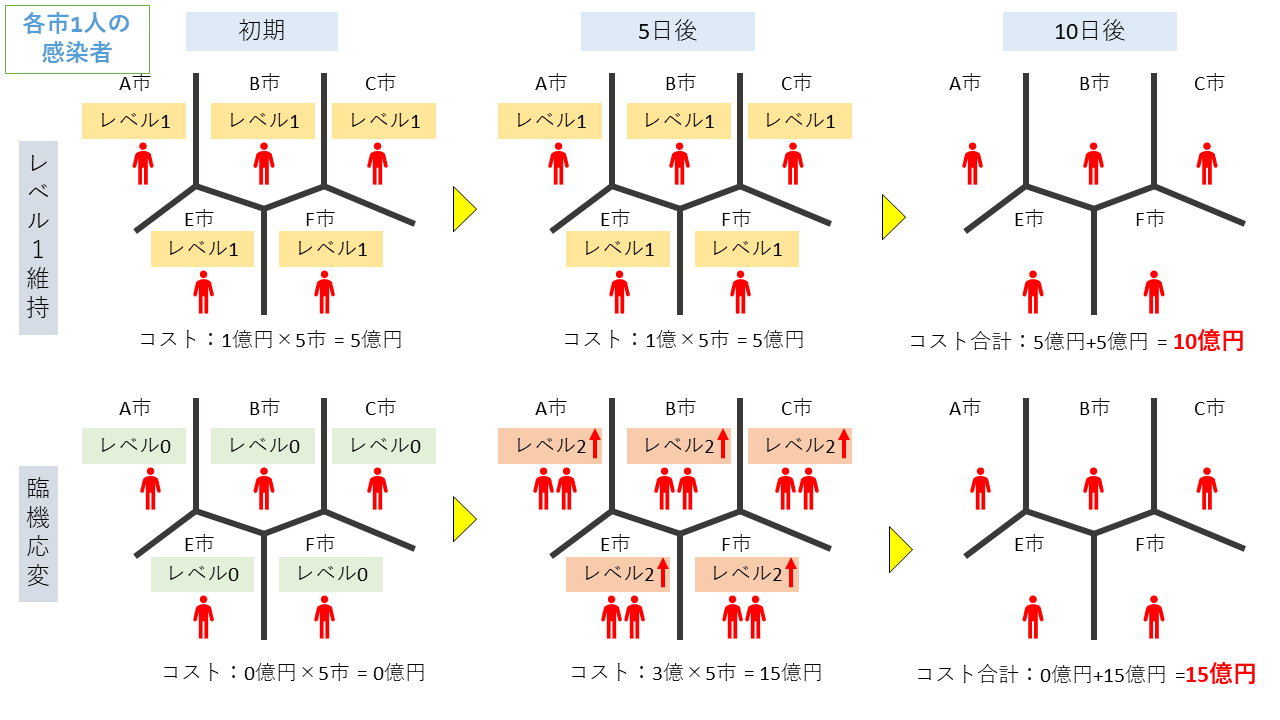
B市のみ1人の感染者の場合
初期条件として、B市のみ1人の感染者がいる場合を想定します。10日後の感染者の人数を初期条件と同じに抑えることを考えたとき同様に2つのケースが考えられます。各市1人の感染者の場合と同様、レベル1を維持し続けるケースと、最初はレベル0で臨機応変にレベル2に変える2つのケースが考えられます。感染者が1人の場合は観測ができない設定なので、初期ではどの市に感染者がいるかわかりません。このため、最初は5つの市全部が同じレベルを設定することにしました。臨機応変のケースでは5日後に、B市で2人になるため感染が観測でき、観測されたB市のみレベル2に変更するとします。この結果、各市1人の感染者の場合と逆で、臨機応変のケースの方が合計コストが小さくなるという結果になっています。
平均のRtみたいのを考えてみる(どう定義していいのかよくわかりませんが)と、1以上になると思うので、感染者が1人より少ない条件ではRtが1以上でも増えない状態がありそうな感じです。
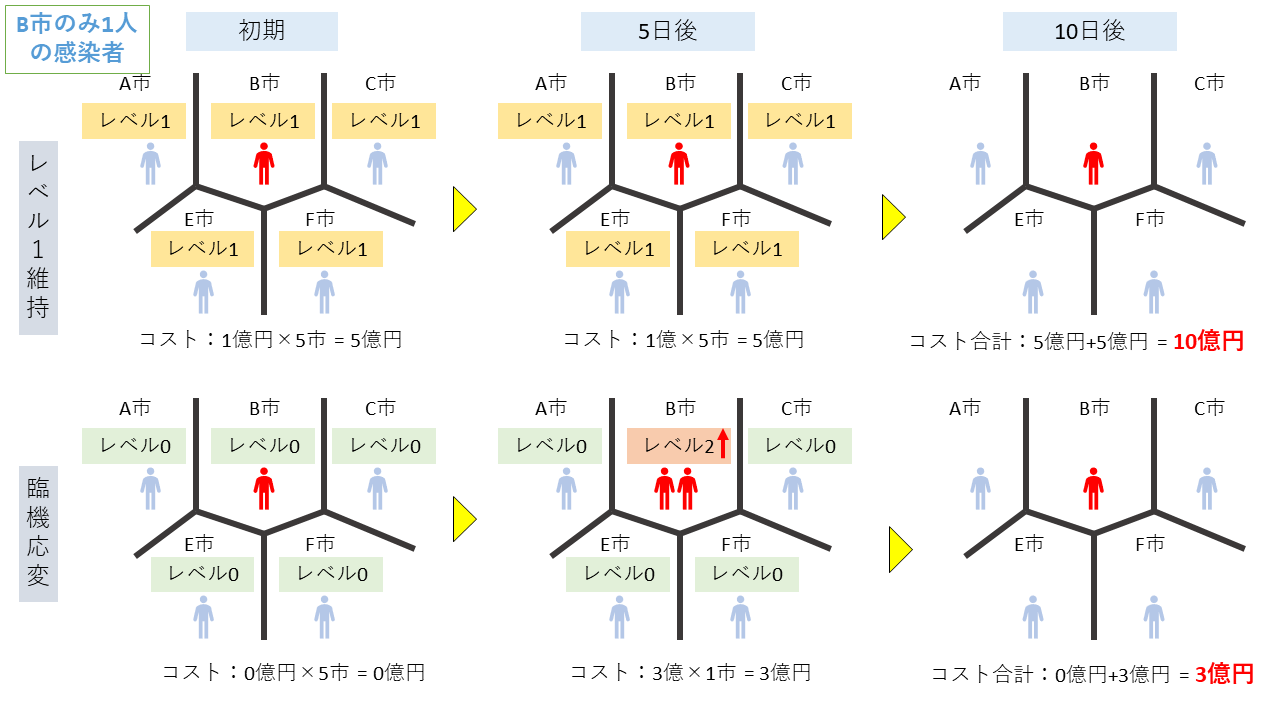
移動範囲と観測範囲
実際、隣の市と行き来がまったくないというのは現実的ではないのですが、ここでは逆に完全自由に移動が起きて、毎日生活する市がランダムに変わるくらいの状態も考えてみたいと思います。この場合、5日後にE市で感染が観測されたとしても、次にどの市で感染が起こるかわからないので、全ての市でレベル2に上げる必要が出てきます。この結果、臨機応変にメリットはなくなり、各市1人の感染者の場合と同じ対応しかできなくなります。元々各市が10万人でしたが、5つの市合わせた50万人単位でしか対応はできなくなり、50万人に1人感染者がいるかいないかが重要になってきます。
どうでもいいことですが、「観測」やその「範囲」で変わることや、感染者が「0 / 1」が重要など、なんとなく量子力学風な感じがして、ちょっと個人的には面白かったりもします。
現実的な方策
ここまでは、理想的な条件のことを考えていましたが、現実的にはどういう風にしたらいいかを考えてみたいと思います。今回の内容から次のような事が考えられます。
- 感染者が1人未満の地域では、経済活動をRt=1時よりも拡大できる可能性がある
- 感染者が1人以上の地域では、経済活動をRt=1時よりも長期的に拡大できない可能性が高い
つまり、
- 感染者が1人未満の期間が長い方が経済的にメリットが大きい
- 感染者が1人以上が観測されたら、すみやかに1未満に抑える方がよい
という結論になります。しかしながら、どの範囲の地域に1人かということが難しく、1つの考えとして、日常行き来をする生活圏を考えてみたいと思います。仕事や買い物、学校など、普段の生活で移動する範囲は地域よって大きく異なると思います。大都市の東京などではそれぞれの生活圏が重なっており、結局大きな範囲で1つの地域とするしかなくなりますが、地方の都市では1つの県を1つの地域として考えることもできるかもしれません。
また、生活圏が別に分かれていたとしても、出張や旅行での移動による感染はゼロにはならないので、他の感染が起きている地域からの流入を考える必要があります。流入により感染者が1未満の地域が1以上になると経済的なダメージは大きいので、そのリスクを減らす必要があると思います。
* 流入リスク = 他地域の感染率 × 移動の人数
ざっくり考えると流入リスクはこんな感じで、地域の感染率とその地域との移動の人数に比例するはずで、感染者が多い地域と行き来を減らすのが妥当な方法になると思います。だたし、他の地域の感染率がほぼゼロで同じなら、移動を減らす必要はないはずです。
結局、地方の県としては
- 自分の県で感染者が出だしたら、出なくなるまでおとなしくする
- 他県で感染者が増えたら、その地域への移動を控える
という当たり前な感じの結論になるのですが、経済重視を掲げる人たちはなぜか逆のことをしたがるので、今回、経済的なメリットも考えてみたかったというところです。
さて、緊急事態宣言が終わった後の5月末から6月にかけては、実際ほとんどの地方都市での市中感染のリスクはゼロになっており、とても平和で快適な生活だったと思いますが、8月の今では大都市からの流入によって、市中感染のリスクに怯えながら生活をしないといけなくなってしまいました。今後、おそらく東京含む大都市の感染はどこかで頭打ちになるとは思いますが、大都市の感染者はゼロなることはないのではないかと思います。一方、地方の県としては上に書いたような感じで自衛しながら、市中感染のゼロを目指すのが、一番リーズナブルな生活送れる方向なのではと思ってます。